

Use Teammaker to form your team. You can log in to that site to indicate your partner preference. Once you and your partner have specified each other, a GitHub repository will be created for your team.
In this lab we will apply deep Q-Learning to two reinforcement learning problems. We will use problems provided by Open AI gym. To start, we will focus on a classic control problem known as the Cart Pole. In this problem, we have a pole attached to a cart and the goal is the keep the pole as close to vertical as possible for as long as possible. The state for this problem consists of four continuous variables (the cart position, the cart velocity, the pole angle in radians, and the pole velocity). The actions are discrete: either push the cart left or right. The reward is +1 for every step the pole is within 12 degrees of vertical and the cart's position is within 2.4 of the starting position.
Once you've successfully been able to learn the Cart Pole problem, you will attempt another problem from Open AI Gym to explore, and write up a summary of your results.
Open the file testOpenAIGym.py and review how to create an open AI gym environment, run multiple episodes, execute steps given a particular action, and receive rewards.
In order to use open AI gym, you'll need to activate the CS63 virtual environment. Then you can execute this file and watch the cart move and see example state information:
source /usr/swat/bin/CS63-10.1
python3 testOpenAIGym.py
NOTE: as with the previous lab, this one will run fastest on a machine with a GPU; however, even more than the previous one this one will be more fun if you've got a graphics connection (i.e. either you're running the code locally, or you've got X-tunnelling set up). You can still do the training without it (just comment out the indicated lines in the source), but it's more fun if you can see the cart-pole balancing simulation live when you're done.
If you want to set up X-tunnelling, there's instructions on the remote access page. If you want to install things locally, check out this page; you'll want to follow the instructions to create a python virtual environment, and then inside that environment you'll want to use pip to install keras, tensorflow, gym, pandas, scikit-learn, and matplotlib (I think this should be all the libraries you need, but if you get import errors when trying to run a file, just use pip to install whatever library it's not finding.
Recall that in Deep Q-Learning we represent the Q-table using a deep neural network. The input to this network represents a state and the output from the network represents the current Q values for every possible action.
Open the file deepQAgent.py. Much of the code has been written for you. There is a class called DeepQAgent that builds the deep neural network model of the Q-learning table and allows you to train and to use this model to choose actions. You should read carefully through the methods in this class to be sure you understand how it functions.
To run this program do (remember you'll first need to activate the CS63-10.1):
python3 deepQAgent.py
If you experience a long delay before the program starts running, keras may be hung up searching for CPU and GPU devices. You can kill the program and try running it like this instead:
CUDA_VISIBLE_DEVICES="" python3 deepQAgent.py
Note that in this case you will not get the computational benefit of using the GPU for that run.
There are two functions that you need to write train and test. The main program, which calls both of these functions, is written for you.
Here is pseudocode for the train function:
create a list to maintain a summary of total rewards per episode
loop over episodes
state = reset the environment
state = np.reshape(state, [1, state size]) #reshape for net
initialize total_reward to 0
loop over steps
choose an action using the epsilon-greedy policy
take the action
observe next_state, reward, and whether the episode is done
update total_reward based on current reward
reshape the next_state (similar to above)
remember this experience
state = next_state
if episode is done
print a message that episode has ended with total_reward
add total_reward to summary list
break
if length of agent's memory > 32
agent replay's 32 experiences
return summary of total rewards
The test function is similar in structure to the train function, but you should choose greedy actions and also render the environment to observe the final behavior. You should also not remember experiences nor replay them during testing, and there's no need to continue updating your model.
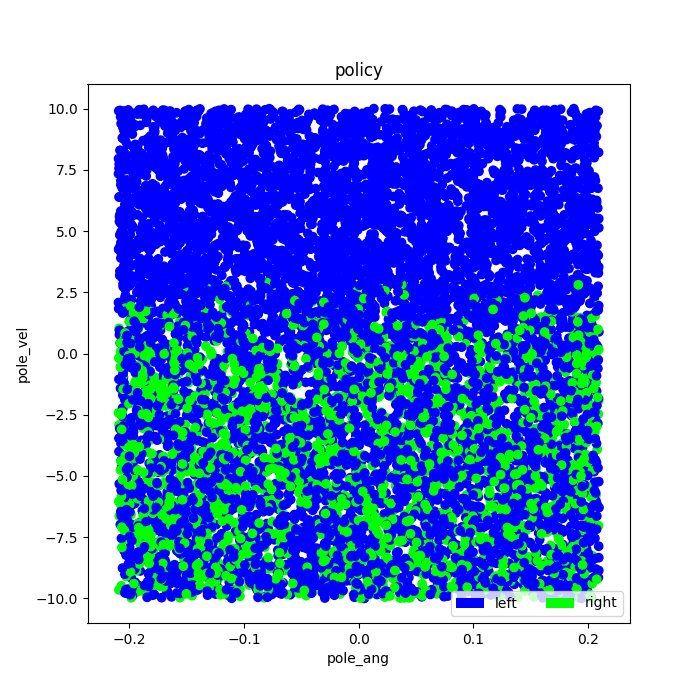
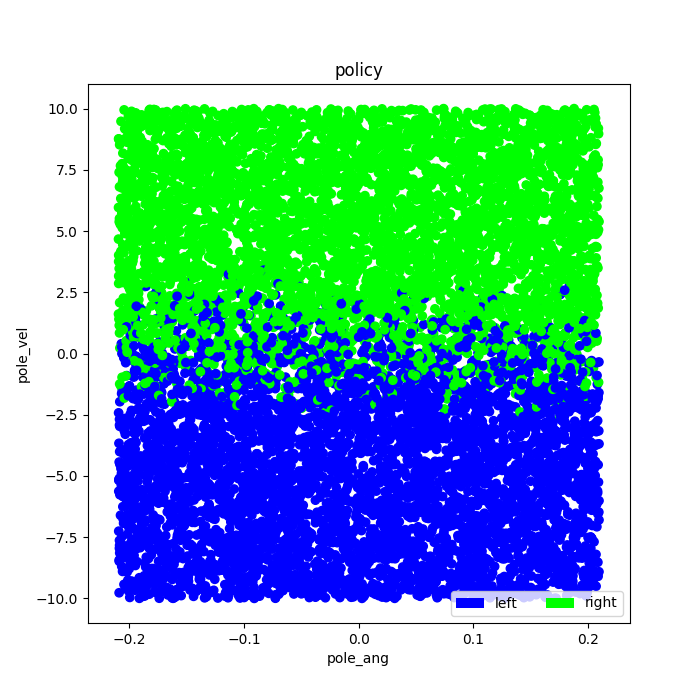
Prior to training, the neural network will be initialized with small random weights, so the Q-learner will start with some random policy. The scatter plot above left shows one such random starting policy. The scatter plot above right shows how the policy changed as a result of training. In these scatter plots the color of a point represents the action that would be taken for a particular pole angle and velocity. Blue indicates a left action and green indicates a right action.
Once you have been able to successfully learn the Cart Pole problem, you should choose another problem to try. Look through the open AI gym documentation and pick a different environment to play with. Remember that reinforcement learning is difficult! We started with one of the easier classic problems. Don't get discouraged if your attempts at a new problem are not as successful.
You should use the testOpenAIGym.py file to test out different domains and to figure out how the states, actions, and rewards are represented.
You may want to make a copy of the file deepQAgent.py, and rename it for your new task. Depending on the state space for the problem you choose, you may need to change the neural network model. For example, if you choose a game with visual input as the domain, you'll likely need to change the input layer to a convolutional layer (you may need to stack several frames as well if the dynamics are important, meaning the input would be 4-dimensional: [X, Y, Color, Frame#]).
Write up a summary or your exploration in the file writeup.tex; you may want to use the .tex files from previous labs as a template.
The analysis of the policy is based on code provided at Solving Mountain Car with Q-Learning
The structure of the Q-learning algorithm is based on code provided at Deep Q-Learning with Keras and Gym