CS91R Lab 03: Statistics in language data
Parts 1 and 2 Due Wednesday, February 19, before midnight
Parts 3 and 4 Due Wednesday, February 26, before midnight
Goals
The goals for this lab assignment are:
-
Learn about types and tokens
-
Learn about Zipf’s law
-
Experimentally determine the accuracy of Zipf’s law
-
Experimentally determine the accuracy of an English spelling rule
-
Learn about the log-odds ratio
-
Experimentally determine differences across corpora using the log-odds ratio
Cloning your repository
Log into the CS91R-S25 github
organization for our class and find your git repository for Lab 03,
which will be of the format lab03-user1-user2, where user1 and user2
are you and your partner’s usernames.
You can clone your repository using the following steps while connected to the CS lab machines:
# cd into your cs91r/labs sub-directory and clone your lab03 repo
$ cd ~/cs91r/labs
$ git clone git@github.swarthmore.edu:CS91R-S25/lab03-user1-user2.git
# change directory to list its contents
$ cd ~/cs91r/labs/lab03-user1-user2
# ls should list the following contents
$ ls
README.md ibeforee.py logodds.py zipf.pyTerminology
1. Copying and modifying Lab 02 files
You will write new program, counts.py that imports the tokenizer.py code
you wrote (and copied over from) Lab 2.
-
Start by copying your
tokenizer.pyfile from last week into this week’s repository. -
Once you have a copy of
tokenizer.pyin this repository, verify that you are using the updated regular expression described in the "Catching underscores" section of Lab 2. -
Add
tokenizer.pyto this week’s repository.
1.1 Counting with a small text-based interface
Your counts.py program should use functions you already created: tokenize,
words_by_frequency, and filter_nonwords. Your program should read from a
file, if provided as a command-line argument, or read from standard in if no
file is provided on the command-line.
Your program should also optionally accept the command-line argument -l,
which determines whether or not to lowercase all of the words before counting,
and the command-line argument -w, which determines whether or not
to keep only the words (filtering the non-words). Both -l and -w can be present,
and you can assume that if they are provided on the command-line, they are
provided before the filename.
The counts.py program will count the words in the text and print to standard
out. The words should be printed from most frequent to least frequent. (Words
with the same frequency can be printed in any order.) The output should
contain, on each line, a single word, followed by a tab, followed by the count
of that word.
Your program should gracefully handle the case where it’s output is piped
to head by catching the BrokenPipeError.
See the slides from lecture 3
for the specific syntax to do that.
Here are some examples of the program running:
# lowercase and filter the words, similar to the output from Lab 2
$ cat /data/cs91r-s25/gutenberg/trimmed/carroll-alice.txt | python3 counts.py -l -w | head -5
the 1643
and 872
to 729
a 632
it 595
# the order of -w and -l doesn't matter
$ cat /data/cs91r-s25/gutenberg/trimmed/carroll-alice.txt | python3 counts.py -w -l | head -2
the 1643
and 872
# using only -l
$ cat /data/cs91r-s25/gutenberg/trimmed/carroll-alice.txt | python3 counts.py -l | head -2
, 2425
the 1643
# using only -w
$ cat /data/cs91r-s25/gutenberg/trimmed/carroll-alice.txt | python3 counts.py -w | head -2
the 1533
and 804
# using no flags
$ cat /data/cs91r-s25/gutenberg/trimmed/carroll-alice.txt | python3 counts.py | head -2
, 2425
the 1533
# providing a file name and both flags
$ python3 counts.py -w -l /data/cs91r-s25/gutenberg/trimmed/carroll-alice.txt | head -2
the 1643
and 872
# providing a file name and no flags
$ python3 counts.py /data/cs91r-s25/gutenberg/trimmed/carroll-alice.txt | head -2
, 2425
the 1533Do not continue to the next section until this is working.
2. Zipf’s law
In this section of the lab, we will test Zipf’s law by using matplotlib,
a 2D plotting library. Put your code for this part in the file called zipf.py.
There are some questions below which you can answer as
you are working through this section.
For full details, read Wikipedia’s article on Zipf’s law. In summary, Zipf’s law states that \(f \propto \frac{1}{r}\) ("\(f\) is proportional to \(\frac{1}{r}\)"), or equivalently that \(f = \frac{k}{r}\) for some constant \(k\), where \(f\) is the frequency of the word and \(r\) is the rank of the word. The terms "frequency" and "rank" are defined below.
1.1 Plotting rank versus frequency
We will be exploring the relationship between the frequency of a token and the
rank of that token. You can use your counts.py program to count the
lowercased words in carroll-alice.txt to get this result:
$ python3 counts.py -l /data/cs91r-s25/gutenberg/trimmed/carroll-alice.txt| Token | Frequency | Rank |
|---|---|---|
|
2425 |
1 |
|
1643 |
2 |
|
1118 |
3 |
|
1114 |
4 |
|
988 |
5 |
Given these results, we would say that the comma , has a rank of 1 since it was
the most frequent token, the word the has a rank of 2 since it was the second-most frequent token,
the open quotation mark “ has a rank of 3, and so on.
Let \(f\) be the relative frequency of the word and \(r\) be the rank of that word.
Assuming you lower-cased the text and didn’t filter out non-words,
the word the occurs 1643 times out of 35830 tokens so
\(f_{\text{the}} = \frac{1643}{35830} = 0.045855\). Since the was the 2nd most
frequent word, \(r_{\text{the}}=2\).
To visualize the relationship between rank and frequency, we will create a
log-log plot of rank (on the x-axis) versus frequency (on the y-axis).
We will use the pylab library, part of matplotlib:
import sys
from matplotlib import pylab
# TODO: read your counts from sys.stdin in this format:
# counts = [(',', 2425), ('the', 1643), ('“', 1118), ('”', 1114), ('.', 988), ...]
label = "alice" # you will use a command-line argument for this
n = len(counts) # n: the number of types
ranks = range(1, n+1) # x-axis: the ranks
freqs = [] # y-axis: the frequencies
for tpl in counts:
freqs.append(tpl[1])
pylab.loglog(ranks, freqs, label=label) # log-log plot of rank vs frequency
pylab.xlabel('log(rank)')
pylab.ylabel('log(freq)')
pylab.legend(loc='lower left')
pylab.savefig(label + '.png') # Save the plot as a PNG file
pylab.show()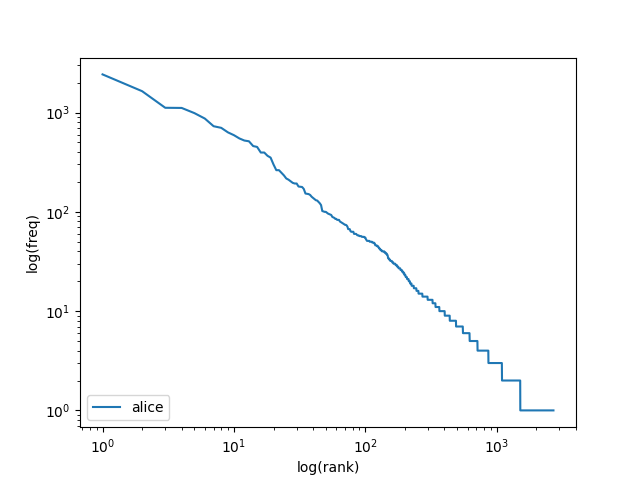
To run your program, use the output of your counts.py program as input
to your zipf.py program. As a command-line argument, provide a name
for your data. Use the name as a replacement for the variable label in
the code above.
# pipe directly into zipf.py
$ python3 counts.py -l /data/cs91r-s25/gutenberg/trimmed/carroll-alice.txt | python3 zipf.py alice
# or save the counts first
$ python3 counts.py -l /data/cs91r-s25/gutenberg/trimmed/carroll-alice.txt > alice.txt
$ cat alice.txt | python3 zipf.py "Alice in Wonderland"1.2 Evaluating Zipf’s law
Now we can test how well Zipf’s law works.
To do so, we will plot the rank vs. empirical frequency data (as we just did above) and also plot the rank vs. expected frequencies using Zipf’s law. For the constant \(k\) in the formulation of Zipf’s law above, you should use \(\frac{T}{H(n)}\) where \(T\) is the number of tokens in the corpus, \(n\) is the number of types in the corpus, and \(H(n)\) is the \(n\)th harmonic number, which you can calcuate using this function:
import math
import numpy
def harmonic(n):
gamma = numpy.euler_gamma
return math.log(n) + gamma + 1 / (2 * n) - 1 / (12 * n**2)According to Zipf’s law, and using our calculated value for \(k\), we get the following: \(f = \frac{k}{r} = \frac{\frac{T}{H(n)}}{r} = \frac{T}{H(n)*r}\)
With this formula, for any rank, \(r\), you can now predict the expected frequency, \(f\), as predicted by Zipf’s law.
To plot a second curve, simply add a second pylab.loglog(…) line immediately after the line shown in the example above.
Questions
-
How many tokens does
carroll-alice.txthave? How many types does it have? -
How well does Zipf’s law approximate the empirical data in
carroll-alice.txt? In addition to your explanation, include the.pngfile that you created in the writeup. -
Choose at least two other texts in the
gutenbergdirectory that you are curious about or think might provide interesting results. Repeat the previous question for these other texts. Include both your explanation of how well you think Zipf’s law approximates these texts, along with the images you created. -
If we concatenated all of the
.txtfiles in thegutenbergdirectory together, we would have a larger corpus with which we could test Zipf’s law. Let’s call this larger corpus "the Gutenberg corpus." Use yourcounts.pyto count all of the.txtfiles in thegutenbergdirectory as a single corpus. Lowercase the words, but do not remove punctuation.-
How many types and how many tokens are in the Gutenberg corpus?
-
Repeat the Zipf’s law experiment with the Gutenberg corpus. Include the
.pngfile you created. -
How does this plot compare with the plots from the smaller corpora?
-
-
Repeat this using the google ngrams counts you built in Lab 02. Include the
.pngfile you created. Note that the code inzipf.pyassumes that your counts are sorted from highest frequency to lowest frequency. -
Does Zipf’s law hold for the plots you made? What intuitions have you formed?
-
In
randtext.py, write a program that generates random text by repeatedly callingrandom.choice("abcdefg "). Create a long string by repeatedly choosing a random character as shown above. There is no specific size string you need to make, but you may need to make the string fairly large in order to see an interesting result. Write this random string out to standard out. You can then use yourcounts.pyprogram to create counts of the random "words" that you make. Use those counts to generate a Zipf plot. Compare this "random text" plot to the plots you made from real text. What do you make of Zipf’s Law in the light of this? Include the.pngfile you created. (Drawn from Exercise 23b, Bird, Klein and Loper)
3. 'i' before 'e' except after 'c'
There is a commonly known rule in English that states that if you don’t know if
a word is spelled with an 'ie' or an 'ei', that you should use 'ie' unless the
previous letter is 'c'. You can read about the
'i' before 'e' except after 'c' rule on Wikipedia
if you haven’t heard of it before. Collecting statistics from text corpora can
help us determine how good a 'rule' it really is. We’ll experiment using
the files in the gutenberg directory.
For this question, either:
-
Write a python program (saved in
ibeforee.py) that reads the counts from stdin, or -
Solve on the command line using tools we’ve learned so far (e.g.
awk,sort,uniq, etc). Put your command-line solution in the README.md file. If you decide to use the command-line, you don’t need to do everything in a single command: you’re welcome to use a few commands to complete it.
3.1 Exploring this rule
We’ll use the counts from "the Gutenberg corpus" that we created Question 4 above. We won’t use the Google ngram corpus in this question because it contains too many misspellings and nonsense words.
Questions
-
Using the Gutenberg corpus described above, compute the fraction of the words that contain 'cei' relative to all words that contain 'cei' or 'cie' by computing \(\frac{\text{count(cei)}}{\text{count(cei)+count(cie)}}\). This most directly answers the question "After a 'c', what’s more likely, 'ie' or 'ei'?" Use type counts when calculating the formula above. What was your result when computing the relative type frequency of 'cei' to all 'cei' or 'cie' words? Is answer what you expected or is it surprising?
-
Repeat the question above using tokens. Does this change your analysis? How?
-
The 'i before e' rule has some exceptions. For example, English words follow the pattern 'eigh' not 'iegh'. Also, many English words end 'ied', 'ier', 'ies' and 'iest' (not 'eid', 'eir', etc.). Recompute your answers to the previous question, but omit any word that contains 'eigh', or any word that ends 'ied', 'ier', 'ies', or 'iest' from your counts. After excluding exceptions, repeat the previous question using tokens. Does this change your analysis? How?
-
Is 'i before e except after c' a good rule? Perhaps there’s a better rule, like 'i before e except after h'? Repeat the previous question, substituting the letter 'c' with all the possible letters. Use token frequencies. Report the relevant results and discuss.
Hint: To iterate through all possible letters, you can use code like this:
for letter in "abcdefghijklmnopqrstuvwxyz": print(letter) -
Data analysis! If you found what you think is a better rule, look through the data to figure out why you think that other rule didn’t catch on. And if you think the "i before e except after c" rule isn’t that good, look through the data and discuss why you think the rule persists (or why it should go).
4. Unigram distributions
In the last section of the lab, we will be using the Google ngram counts we created last week to determine which words are over- or under-represented in the Gutenberg novels relative to the counts Google has collected across millions of books.
To do this, we will compare the probability that a word is in the Google
corpus to the probability that word is in another document such as shakespeare-hamlet.txt.
Words that have a much higher probability in Hamlet relative to
Google’s counts are words that are over-represented. Words that have a much
higher probability in Google’s corpus than in Hamlet are under-represented.
Calculating probabilities
To start, we need to calculate the probability of seeing a word in a corpus. To do so, we simply count how many times the word occurred in the corpus and divide it by the total number word tokens in the text. (Be sure to use word tokens and not word types.) In the equation below, \(w\) is a variable used to represent a single word in the text:
Calculate the probability \(p_\text{hamlet}(w)\) for every word in the Hamlet corpus, and calculate \(p_\text{google}(w)\) for every word in the Google corpus in the same way:
Note: The probabilities you will calculate are very small. For example, the
probability of seeing the word apple, a fairly common English word, is just
0.000012 in the Google corpus. For less common words like yellowness,
the probabilty is 0.000000092.
Log Odds Ratio
A common way to compare two probabilities is to calculate a Log Odds Ratio. To calculate the Log Odds Ratio, we calculate the probability of seeing a word in the Hamlet text and divide it by the probability of the same word in the Google corpus, then take the \(log\) of that ratio.
It doesn’t make sense for us to just subtract the two probabilities and calculate the difference because the probabilities are so small.
Instead, we will find the ratio of one probability to the other and then take the \(log\). For ratios that are greater than 1, the \(log\) will return a positive number. For ratios that are less than 1, the \(log\) will return a negative number.
Assuming you’ve calculated the probabilities for every word in both corpuses as described in the previous section, you can calculate the Log Odds Ratio as follows:
Notice that it is a problem if \(p_\text{google}(w) = 0\), since you’d be dividing by zero. It’s also a problem if \(p_\text{hamlet}(w)=0\) since you would then need to compute \(\log(0)\), which is undefined.
To make sure neither of these happen, we will add a very small number, \(\epsilon\), to the top and bottom of the ratio. When we do this, we say we are smoothing the data. In particular, this particular method of smoothing is called LaPlace smoothing or additive smoothing.
Let’s set \(\epsilon = 0.00001\) and recalculate the Smoothed Log Odds Ratio:
Interface
To run your logodds.py program, you will provide two files as command-line arguments.
Each file will contain the counts in the same format as you made using counts.py.
For example, to compare Hamlet to Alice in Wonderland, you could say this:
$ python3 counts.py -w /data/cs91r-s25/gutenberg/trimmed/carroll-alice.txt > awords.txt
$ python3 counts.py -w /data/cs91r-s25/gutenberg/trimmed/shakespeare-hamlet.txt > hwords.txt
$ python3 logodds.py awords.txt hwords.txtRather than reading your counts into a list of tuples, you will need to read your counts into a python dictionary, that way you can easily look up the count for any word in both corpora.
Questions
Compare "Alice in Wonderland" to "Hamlet".
-
Look through the 50 (or so) most over-represented words in Alice in Wonderland. Do these words surprise you? Do the over-represented words follow a particular pattern?
-
Repeat for the 50 (or so) most under-represented words in Alice in Wonderland. Do these words surprise you? Do the under-represented words follow a particular pattern? Is the set of under-represented words more or less surprising (to you) than the over-represented words? Do they follow the same pattern as the over-represented words?
-
Look at the words that are somewhat equally represented in Alice in Wonderland and Hamlet. Do these words surprise you? Do they follow a particular pattern?
-
Repeat the three questions above but this time compare two books written by the same author (Austen, Chesterton, and Shakespeare each have multiple books in that directory). Are the patterns the same or different?
Now we’ll compare all three of Shakespeare’s plays (in that directory) to the
entire Google ngrams counts. That should give us a sense of the kind of words
that Shakespeare used that are different than other book authors.
To do that without uncompressing your ngrams counts file,
you’ll need to do something like this (assuming your Shakespeare counts
are in shakespeare.txt and your compressed google counts are in /scratch/user1/all_sorted.txt.gz)
$ python3 logodds.py shakespeare.txt <(gzcat /scratch/user1/all_sorted.txt.gz )This may a minute or so depending on your implementation.
There are a lot of words in the ngrams corpus. This
will also generate a lot of output, so you should save the output to a file
in your /scratch directory. Do not check this output file into your repository!
-
Re-answer questions 13, 14 and 15 with this new output.
-
OPTIONAL: Repeat this for any other texts that interest you and report your results.
How to turn in your solutions
Edit the README.md file that we provided to answer each of the questions
and add any discussion you think we’d like to know about.
Be sure to commit and push all changes to your python files.
If you think it would be helpful, use asciinema to record
a terminal session and include it your README.md.
See Lab 1 for a reminder of how to use asciinema.