Week 9: searching
This week is searching and next week is sorting. For both of these topics there are multiple algorithms to accomplish the task (searching and/or sorting data). In addition to learning and coding a few searching and sorting algorithms, we are going to start analyzing algorithms. By this I mean classifying algorithms into broad categories so we can compare one algorithm versus another.
Monday
The video from today’s lecture (Monday, March 30, 2020):
And here are the annoucements:
-
almost done with Quiz 3 grading, will send that out later today. Look for an email from gradescope.com
-
Quiz 4 has been moved back a little, to next week. Also, it will be online (write a few programs or functions), and you will be able to take it anytime next week. More details later this week (and the Quiz 4 study guide will be posted later this week).
-
I’ve made comments and replied to all TDD emails. If you still need help with your design, let me know. Otherwise you are free to keep working on the game (due Saturday).
linear search
When searching for an item in a list, a simple search involves looking
at each item in the list to see if it is the one you want. Here’s a
function to search for x in a list L:
def linearSearch(x,L):
"""return True if x is found in L, False if not"""
for i in range(len(L)):
if L[i] == x:
return True
# if we get here, past the for loop, x is not in L
return FalseThe function above only says if the item we are looking for is in the list or not. Other searches might be interested in where the item is in the list (if at all), or how many of the item are in the list.
We talked a little about linear algorithms last Friday. This is called linear search because the number of steps or operations carried out by that function is directly proportional to the size if the list.
For example, if there are 100 items in the list, in the worst case, the
for loop with run 100 times. If we double the size of the list to
200 items, the for loop will take twice as long.
binary search
If our data is already sorted from low to high, is there a better way to
search for x in L?
L = [5, 16, 33, 34, 60, 89]
If we are searching for x=20, there is no point searching
past the 33, since we know the list is sorted from low to high, and
we are already past what we are looking for.
Here is another example: if I say "I am thinking of a number from 1 to 100", and when you guess, I will tell you if you are too high or too low, what is the first number you would guess?
A linear search would guess one number at a time, from 1 to 100.
A binary search would pick the middle and first guess 50. If that is too low, we can then concentrate on the upper half (51-100), and we have already eliminated half of the list! In a binary search, each guess should split the remaining list in half, and eliminate one half.
binary search pseudo code
Here is the pseudo-code for binary search (searching for x in list):
set low = lowest-possible index
set high = highest possible index
LOOP:
calculate middle index = (low + high)//2
if x is at middle index, we are done (found it! return True)
elif x is < middle item,
set high to middle index - 1 # eliminate top half
elif x is > middle item,
set low to middle index + 1 # eliminate bottom hald
if low is greater than high, x is not here (done, return False)
And here is an example of how the low, mid, and high indices change as the search is happening:
x = 99 L = [-20, -12, -4, 1, 7, 44, 45, 46, 58, 67, 99, 145] index: 0 1 2 3 4 5 6 7 8 9 10 11
| low | high | mid | L[mid] | explanation |
|---|---|---|---|---|
0 |
11 |
5 |
44 |
x is > 44, so low becomes mid+1 (6) |
6 |
11 |
8 |
58 |
x is > 58, so low becomes mid+1 again (9) |
9 |
11 |
10 |
99 |
x is == 99, so return |
And here is an example where the item we are searching for is not in the list. The search keeps going until low is greater than the high index.
x = -10 L = [-20, -12, -4, 1, 7, 44, 45, 46, 58, 67, 99, 145] index: 0 1 2 3 4 5 6 7 8 9 10 11
| low | high | mid | L[mid] | explanation |
|---|---|---|---|---|
0 |
11 |
5 |
44 |
x is < 44, so high becomes mid-1 (4) |
0 |
4 |
2 |
-4 |
x is < -4, so high becomes mid-1 again (1) |
0 |
1 |
0 |
-20 |
x is > -20, so low becomes mid+1 (1) |
1 |
1 |
1 |
-12 |
x is > -12, so low becomes mid+1 (2) |
2 |
1 |
low is > high, so return |
edit searches.py
Let’s write our two search functions, linearSearch(x,L) and
binarySearch(x,L), in a file called searches.py.
Then we can import this file and use those
functions in other programs.
If we put these two functions in a file called searches.py,
then we can say from searches import * in other programs
and be able to use those two search functions!
Here is the start of searches.py, with the linearSearch(x,L) function
in it.
def linearSearch(x,L):
"""return True if x is in L, False if not"""
for i in range(len(L)):
if L[i] == x:
return True
# only gets here if not found!
return False
# add binarySearch(x,L) herewrite lookfor.py
The lookfor.py program reads in the wordlist we have used before (in
/usr/share/dict/words) and then asks the user for a word. Once we have
a word from the user, we can use our binarySearch(x,L) function to
check if it’s a valid word.
Here’s a run of the program:
$ python3 words.py word to search for: hello FOUND! word to search for: zebra FOUND! word to search for: skdjfkldjfl not found... word to search for: $
And here’s the source code:
def main():
words = read("/usr/share/dict/words")
# get word from user
# search for it in words list
done = False
while not done:
word = input("word? ")
if word == "":
done = True
else:
result = binarySearch(word,words)
if result:
print("FOUND!")
else:
print("not found...")
def read(filename):
"""read words from file, return as list"""
inf = open(filename)
lines = inf.readlines()
inf.close()
words = []
for line in lines:
words.append(line.strip())
return words
main()algorithm comparison
What’s the worst-case number of times the while loop will run in the
binary search? If each time we are splitting the data in half, that’s
the same as asking "how many times can I divide the data in half before
there is only 1 item left?"
For example, if N=len(L), and we have 16 items in the list,
then how many times can we divide the data in half?
16 8 4 2 1
So four times we can split the data in half, leaving us with just one item left. Mathematically, that can be calculated using log-base 2 of N.
>>> from math import * >>> log(16,2) 4.0
What’s interesting is if we start with 32 items (twice as much data), it’s only one extra iteration:
>>> log(32,2) 5.0
Here’s a comparison of the two search algorithms (keep in mind, using the binary search means we have to have the data in order first, so we might need to sort the data (next week’s topic)).
| N = len(data) | linear search worst case | binary search worst case |
|---|---|---|
64 |
64 |
6 |
128 |
128 |
7 |
256 |
256 |
8 |
512 |
512 |
9 |
Binary search worst case (how many iterations it will take) is just
log-base 2 of N, where linear search worst case is N.
>>> from math import * >>> log(64,2) 6.0 >>> log(512,2) 9.0 >>> log(1000000,2) 19.931568569324174 >>> log(2000000,2) 20.931568569324174
So for 1 million items, only around 20 iterations! Linear search worst case for 1 million-item list is 1 million iterations!!
questions?
Some great questions from the video chat!
-
does
//round up or down?-
rounds down since it is integer division. So
5//2=2
-
-
What if odd number of items in list?
-
odd number of items don’t need rounding down (it would just be the middle element); for example if there are 9 items then mid would just be (0+8)//2 = 4; an even number of items would need rounding down, e.g. if there are 4 items, the mid = (0+3)//2 = 1
-
-
can you explain how you got binarySearch in lookfor.py
-
the
from searches import *is what does that, since we wrote ourbinarySearchfunction in the filesearches.py
-
-
when you import the words list are the words already in an order?
-
yes, the words in
/usr/share/dict/wordsare already in alphabetical order (with the capitalized words all first, then the lowercase words)
-
-
what does
if resulttest?-
in our code we have
result = binarySearch(x,L), and the binary search function returns eitherTrueorFalse. So usingif resultworks because ourresultvariable holds a boolean. If the result is True, theifblock is executed, otherwise theelseblock gets run
-
Wednesday
The video from today’s lecture (Wed, April 1, 2020):
Quiz 3
I finished the grades on gradescope and sent them out. If you run
handin21 you should get a q3.py file. Here are the answers to
questions 2, 3, and 4:
Question 2: deleting the else case is one way to fix the function.
def alldigits(string):
digits = list("0123456789")
ALLDIGITS = True
for i in range(len(string)):
if string[i] not in digits:
ALLDIGITS = False
# else:
# ALLDIGITS = True
return ALLDIGITSQuestion 3: write the main() function:
def main():
done = False
count = 0
total = 0
while not done:
word = input("word? ")
if word == "-1":
done = True
else:
total = total + len(word)
count = count + 1
avgwl = total / count
print("Avg word length = ", avgwl)Question 4: write the index(letter,string) function:
def index(letter, string):
for i in range(len(string)):
if string[i] == letter:
return i
# if we get past the for loop, letter is not found
return -1binary search worksheet
See the searchWorksheet file for some sample binary searches.
In that file we want you to show the binary search as it happens:
write in low, high, mid, and L[mid] for each pass through the loop.
Here’s the first example:
x = 99
L = [-20, -12, -4, 1, 7, 44, 45, 46, 58, 67, 99, 145]
index: 0 1 2 3 4 5 6 7 8 9 10 11
low mid high L[mid]
0 5 11 44 99 > 44 so make low = mid + 1
6 8 11 58 99 > 58 so make low = mid + 1 again
9 10 11 99 FOUND!
analysis of algorithms
See the algorithms.py file, try to classify each algorithm as either
constant time, logarithmic, linear, loglinear, or quadratic.
Here’s the first two:
# 1 LINEAR (if you double N, takes twice as long)
N = int(input("N: "))
for i in range(N):
print(i)# 2 CONSTANT TIME (N doesn't matter, always 100 prints)
N = int(input("N: "))
for i in range(100):
print(i*N)See our graph of functions for how "number of steps" changes as N gets larger for each algorithm.
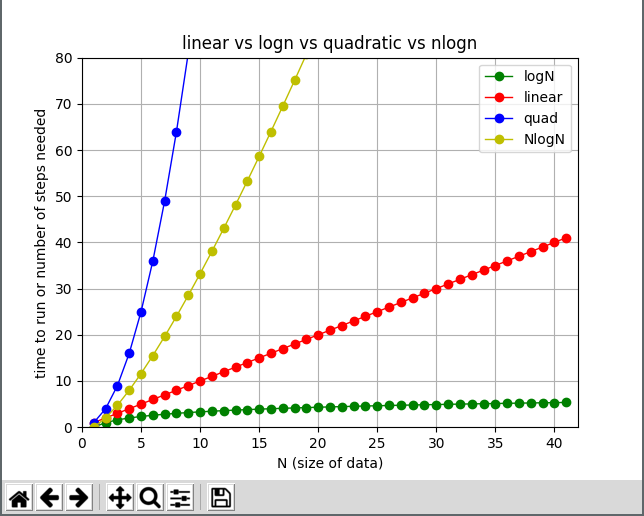{kind=link}
And here’s one more:
# 4 QUADRATIC
N = int(input("N: "))
for i in range(N):
for j in range(N):
print(i, j)Do you see why this one is quadratic? If you were to show i and j as
the two loops execute, you would get something like this (assume N=5):
i 0 j=0,1,2,3,4 1 j=0,1,2,3,4 2 j=0,1,2,3,4 3 j=0,1,2,3,4 4 j=0,1,2,3,4
When i=0, the inner j loop goes from 0 to 4, since the j loop
is nested inside the i loop. Same for when i=1,
i=2, and so on. If we double the size of the data (N=10) the above
outputs of i and j would be four times larger.
Friday
The video from today’s lecture (Fri, April 3, 2020):
Outline
-
quiz practice: if you run
quiz21, you should get a newcs21/S20Quizzes/practicedirectory with two python files in it. Edit and run the python files as practice for the quiz (you can also runhandin21when you finish them) -
finish 7,8,9 of
algorithms.py -
slicing: something useful we usually cover earlier in the semester. Slicing will be used a lot in two weeks when we cover recursion.
more analysis of algorithms
See the algorithms.py file, try to classify each algorithm as either
constant time, logarithmic, linear, loglinear, or quadratic.
Here are two more from the file:
# 7
N = int(input("N: "))
while N > 1:
print(N)
N = N/2The above is an example of a logarithmic algorithm (O(logN)). The loop
keeps going as long as N > 1, and each time through the loop we divide
N by 2. So the total number of times we execute the loop block is
log(N) (technically log-base-two of N).
The binary search is also an example of a logarithmic algorithm. In the worst case we start with a list of data and keep dividing it in half until there’s no data left (i.e., whatever we are looking for is not in the list).
# 9
N = int(input("N: "))
for i in range(N):
k = N
while k > 1:
print(i, k)
k = k/2This one is just a combination of linear and logarithmic. Some people
call it loglinear, or linearithmic. I usually just writ O(NlogN). The
outer for loop is the linear part, and the inner while loop is the
logarithmic part.
slicing
Slicing is similar to indexing, but we specify a range of indices, instead of just one number. Like indexing, slicing works on string and lists.
>>> L = list("ABCDEFGHIJ")
>>> S = "we love computer science"
>>> L[3]
'D'
>>> S[3]
'l'
>>> L[3:8]
['D', 'E', 'F', 'G', 'H']
>>> S[3:8]
'love '
There are also some useful shortcuts: if you leave off the start, python assumes a start of 0, and if you leave off the stop, python assumes the end of the list or string:
>>> L[:5] ['A', 'B', 'C', 'D', 'E'] >>> L[5:] ['F', 'G', 'H', 'I', 'J'] >>> S[:5] 'we lo' >>> S[5:] 've computer science'
Slicing is an easy way to grab part of a string or list. Here’s a silly example: get the user’s first and last name, make a (fake) ITS username.
$ python3 its.py first name: abe last name: lincoln Your ITS username is alincol1
Here’s the code for that program:
def main():
first = input("first name: ")
last = input(" last name: ")
username = first[0] + last[0:6] + "1"
print("Your ITS username is %s" % (username))Another silly example: get a string from user, display it half above and half below the line.
$ python3 stringsplit.py
string: we love computer science!!!!
we love comput
++++++++++++++++++++++++++++
er science!!!!
For that one we can use the len() function to get the length of the input
string, the calculate the middle index and use slicing to get the first
and second half of the input string.
A more realistic example: ask user for 3-letter codon, look for codon in given RNA strand (search each group of 3 letters).
$ python3 strands.py
The RNA Strand is: CACGCAGGCAUGCAGUAAAGUUCUACAUGAGCC
look for? AUG
Looking for: AUG
CAC
GCA
GGC
AUG
CACGCAGGCAUGCAGUAAAGUUCUACAUGAGCC
^
Found it!
CAG
UAA
AGU
UCU
ACA
UGA
GCC